まずは下の画像を比べてください
クリックして拡大




VIDVIPプロジェクトで開発したデータセットは国内における歩道移動時における歩行者目線の画像データから物体検出のアノテーションを行いました。横断歩道(crosswalk)、ガードレール(guadrail)、歩行者用信号が青であることを認識している様子がわかります。視覚障害を持つユーザにとって安全な歩道移動時に必要な情報は汎用データセットではカバーできないため、本研究では屋外移動時における視覚障害支援に必要なクラスラベルからなるデータセット開発を行いました。本プロジェクトでは物体検出と領域検出の2種類のデータセットを開発しており、領域検出を利用することで、視覚障害者が歩道の中心を歩いているか、車道に近づきすぎていないか等も認識することが可能になります。
物体検出DEMO
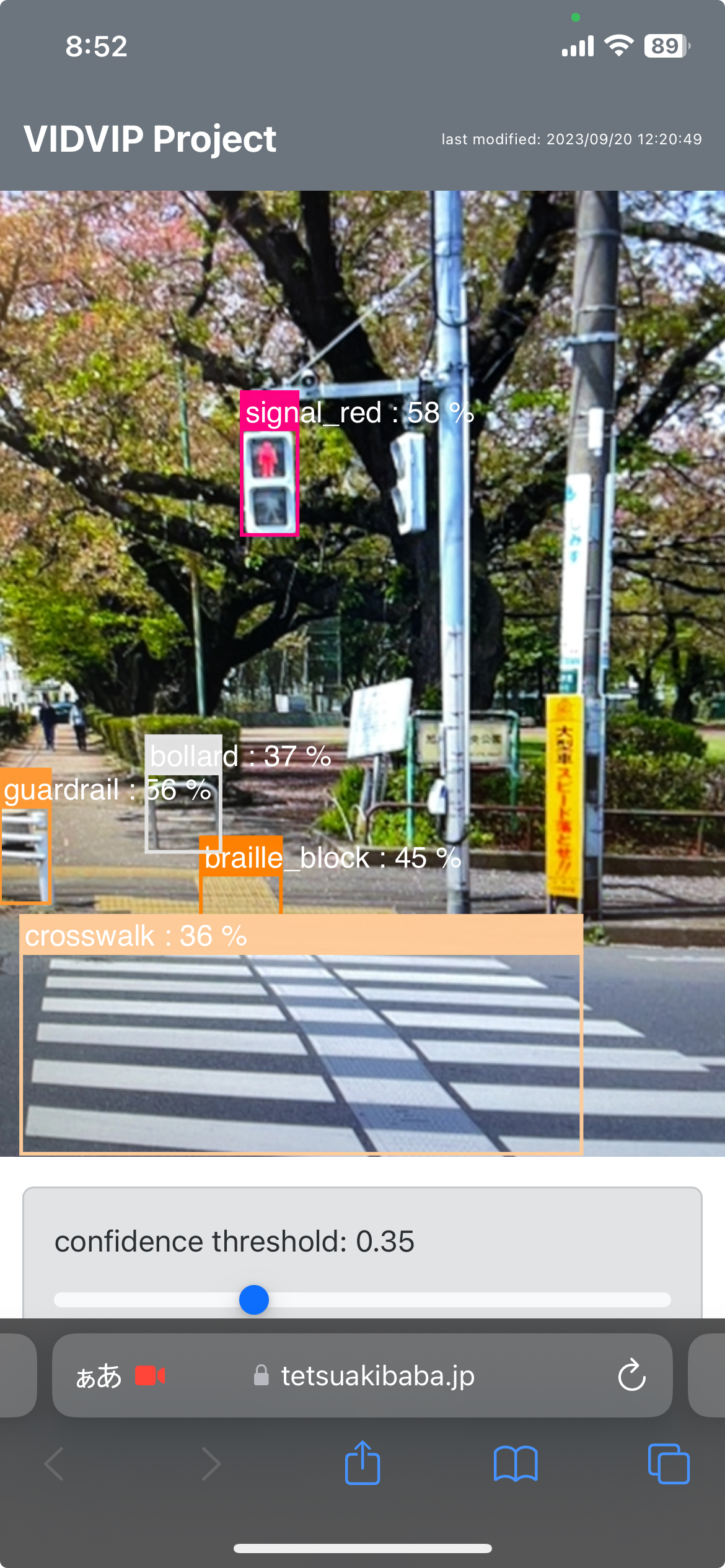
ブラウザ上で物体検出学習済みモデル(Mobilenet)を試すことができます。iPhoneやandroid等のスマートフォンやカメラ付きタブレットやPCから
Google社による
Mediapipeを利用しており、mediapipe-model-maker
を利用して MOBILENET_V2_I320 で学習したものです。学習モデルは5MB程度の軽量モデルの為、
ブラウザ上で動作することから、プロトタイプツールとしてもご活用ください。ソースコードは github 上にて公開されています。
学習済モデルをダウンロード
現在物体検出器(vidvipo)及び領域検出器(vidvips)による学習済みモデルを提供しています。学習済みモデルの種類はweights, pt, mlmodel等があり、VIDVIPプロジェクトチームがアノテーションした独自データセットのみを基に作成されています.より精度の高いモデルや,認識ラベルの拡張などはプロジェクト代表者に別途ご相談ください.

この 学習済みモデルは クリエイティブ・コモンズ
表示 - 非営利 - 改変禁止 4.0 国際 ライセンスの下に提供されています。
現在提供している学習済みモデル
vidvipoは物体検出、vidvipsは領域検出を行うモデルです。それぞれのモデルはpytorch, coreml, darknetの3種類の形式で提供しています。vidvipoでは39クラス 、vidvipsでは41クラス を認識します。
- vidvipo_yolov8n_2023-05-19.pt pytorch
- vidvipo_yolov8x_2023-05-19.pt pytorch
- vidvips_yolov8n-seg_2023-09-20.pt pytorch
- vidvips_yolov8m-seg_2023-09-20.pt pytorch
- vidvipo_yolov2_20210521.mlmodel coreml
- vidvipo_yolov8x_2023-05-19.mlmodel coreml
- vidvipo_yolov8n_2023-05-19.mlmodel coreml
- vidvips_deeplabv3_20230316.mlmodel coreml
- vidvipo_yolov2-tiny.weights.zip darknet
データセットをダウンロード
データセットの利用は
データセットのダウンロードは VIDVIPデータセット利用申請 を通じて行ってください。申請時に所属や利用用途を記載する欄がありますので、なるべく詳しくご入力お願いいたします。入力情報によってはこちらから改めて追加情報提供をお願いする場合があります。
提供するデータセットは物体検出用途で、約30,000枚の画像に対して50万アノテーションが付与されています。アノテーションは物体の位置とクラスの情報を含んでいます。アノテーションの詳細は githubページの names_c39.txt をご参照ください。なお VIDVIPのgithubリポジトリサイトでは各データセット変換等に利用するpythonスクリプト等も提供していますので、必要に応じてご活用ください。
2023年9月20日現在現在、
データセット開発に参加
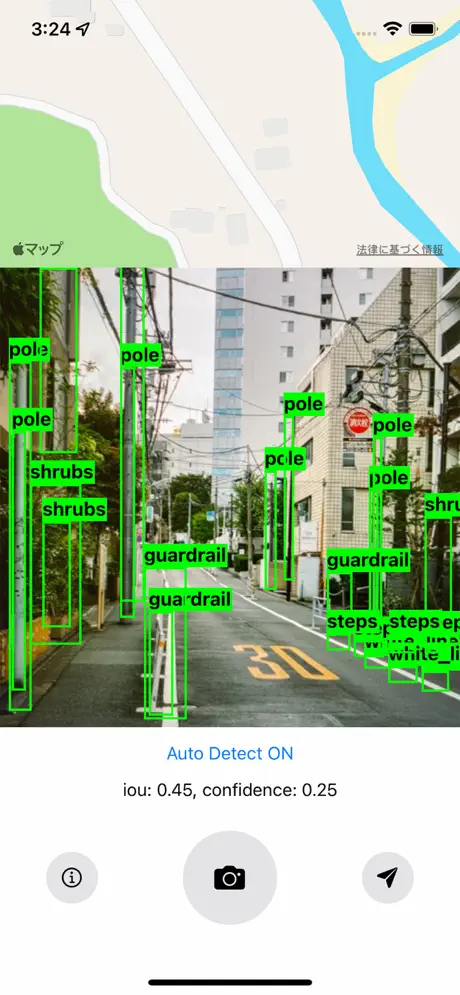

iOSアプリケーションをダウンロードして、あなたの通勤,通学,お散歩時における目線から撮影した画像を送ってください。わたしたちはそれらデータを利用し、さらに学習モデルの品質向上を行います。 アップロードされたすべてのデータはニューラルネットの学習に利用されるのみであり,一切公開されることはありません.アップロードされた画像やデータに関する個人情報の扱いについては Policies and Guidelinesを参照してください。
プロジェクトについて

このプロジェクトは視覚障害を持つユーザの屋外移動支援を目的としてスタートしました。盲導犬や介助者が同行するように、身の回りの障害物をリアルタイムに検出することで、単独移動時でも安全な支援を目指しています。それらの実現に向け,自動運転のようなコンピュータビジョンの為のデータセットが必要と考え,本プロジェクトでは歩道上の移動に特化した物体検出データセットの開発をはじめました.例えば点字ブロックや横断歩道、歩行者用信号の色等を高精度に認識することができます。
データセットには主に物体検出と領域分割の2種類を開発しており、現時点(2023年4月24日)では、物体検出では日本国内の3万枚の画像に対して、50万のアノテーションがなされています。また領域検出では6,000枚の画像に対して10万のアノテーションがなされています。日本国内のデータセットの詳細は VIDVIPデータセット及び学習モデルの詳細を知る にて確認ができます。
VIDVIPプロジェクトでは、データセットや学習済みモデルの提供を通じ、視覚障害支援技術を共創デザインにより、持続可能な社会実装を目指しています。支援技術開発には大きなコストがかかる一方で、ユーザ数の少なさからこれまで経済原理によって支援技術の開発が進んでこなかったという背景があります[1]。技術発展により、「一人のためのデザイン」が可能になった現在、データセットを共創メディアとしてこのプロジェクトでは支援技術の共創デザイン化に取り組みます。
Reference
[1] 馬場 哲晃 , 島影 圭佑 , 本多 達也 , 田中 浩也,あなたのためのデザイン:デジタルファブリケーションが可能にする身近な人の為の福祉機器プロダクト,研究報告アクセシビリティ(AAC),2017-AAC-4(12),1-4 (2017-08-19) , 2432-2431 [PDF]
利用例:Eye Navi
VIDVIPプロジェクトのスタート時から連携している、株式会社コンピュータサイエンスによるスマートフォンアプリケーションです。本アプリケーションは、歩道上の障害物を検出し、ユーザに音声で伝えることで、視覚障害者の歩道移動を支援します。リアルタイム物体検出器開発にVIDVIPプロジェクトのデータセットを利用しています。

VIDVIPデータセット及び学習モデルの詳細を知る
最新のVIDVIPデータセットを利用して生成した学習モデルの精度やデータセットの質的評価に関して、mAPやデータの統計的性質からまとめています。現時点では物体検出に関わる内容のみを報告しています(2023年4月24日)。
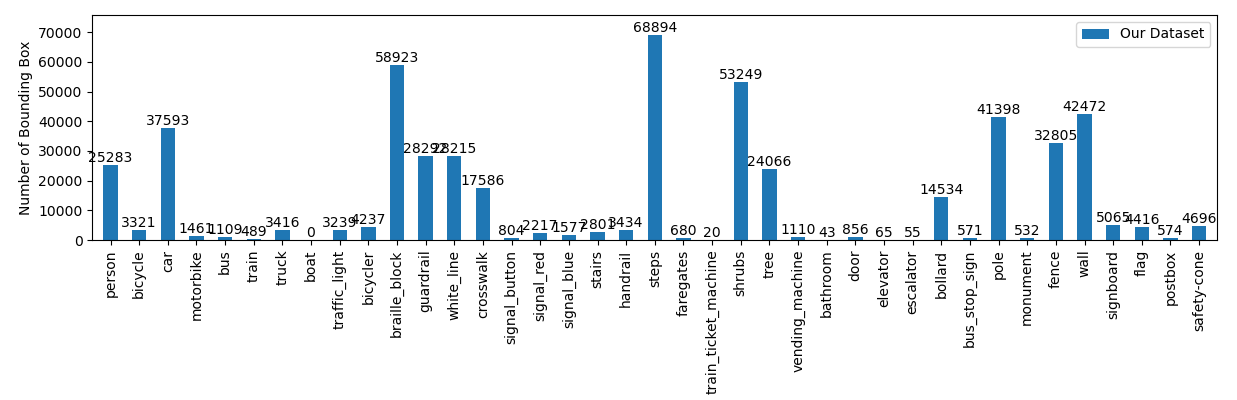
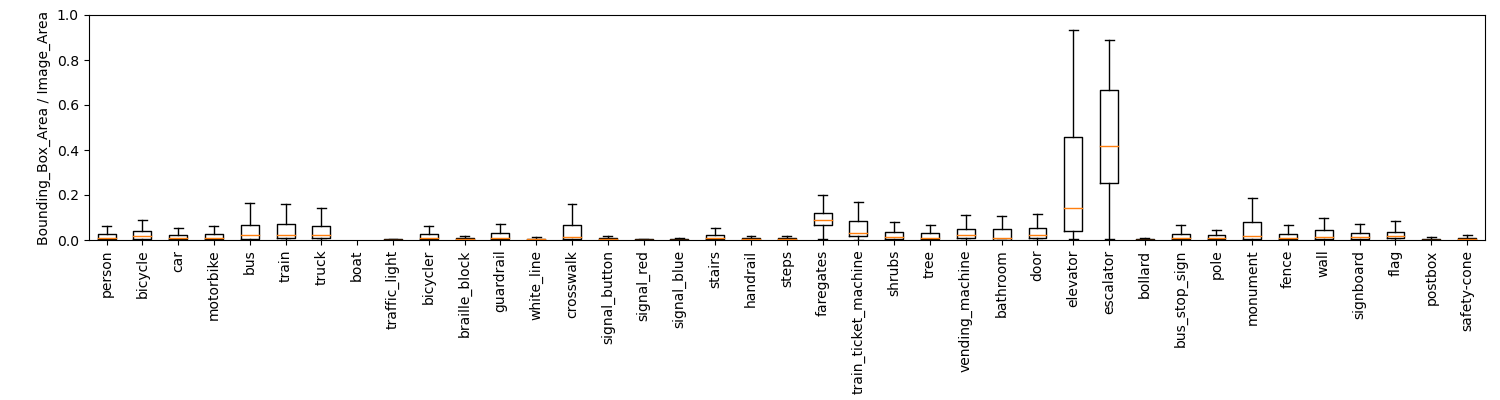
2023年4月24日現在、30,471枚の画像に対して、520,098箇所のインスタンス数(アノテーションされたバウンディングボックスの数)となっています。図1にはそれぞれの認識ラベルのインスタンス数、図2には各インスタンスの画像に対する面積比率を示します。VIDVIPデータセットは比較的自動運転用途のデータセットに近い性質がありますが,クラスラベルは視覚障害支援に特化した物体検出ラベルを中心にアノテーションされています.例えば図3は汎用データセットCOCOと同じ画像での認識結果を比較したものです.人や自転車の他,VIDVIDデータセットでは点字ブロックや歩行者用信号,横断歩道を認識している様子がわかります.
誰がアノテーションしていますか?
アノテーションの品質は極めて重要です。認識ラベルの誤りが無いことはもちろん、精確なアノテーションがなければ障害物のズレが生じたり、安全性の高いガイドを提供することが困難になります。大規模データセット開発にはしばしばクラウドソーシングが活用されますが、低賃金労働によるデータセット開発ではその質の低下が近年問題視されており、例えば画像データセットとして有名なImageNetでは全体の6%にあたる2916箇所のラベル誤りが報告されています[1]。VIDVIPプロジェクトでは研究代表者である馬場哲晃研究室の中で、十分な訓練を積んだ学生がアノテーション作業を行い教員が目視チェックを一枚一枚行っています、さらには人工知能技術によるデータ整合性チェック等を合わせて行うことで高品質なデータセット開発を実現しています。
[1] Curtis G. Northcutt and Anish Athalye and Jonas Mueller, Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks,2021,2103.14749,arXiv [paper]
文献
本プロジェクトに関する文献は以下の参照、引用をお願い致します。
- T. Baba, “VIDVIP: Dataset for Object Detection During Sidewalk Travel,” J.
Robot. Mechatron., Vol.33 No.5, pp. 1135-1143, 2021. https://doi.org/10.20965/jrm.2021.p1135
@article{ Baba_2021jrm, title={VIDVIP: Dataset for Object Detection During Sidewalk Travel}, author={Tetsuaki Baba}, journal={Journal of Robotics and Mechatronics}, volume={33}, number={5}, pages={1135-1143}, year={2021}, doi={10.20965/jrm.2021.p1135} }